How I went from 46% to 94% accuracy by evaluating four parser architectures and and approaching NLP as a system with measurable trade-offs.
Why This Matters
I've been building Trip Threads, a conversational travel planner designed to solve the coordination chaos of group trips. Natural language input quickly became the defining feature of the platform with the hypothesis being that if users could type things like "Dinner €60 split 4 ways" or "Flight to Paris Monday 9am" and the system just handled the rest, the experience would be dramatically faster than traditional forms.
But implementing a parser that works across messy real-world input turned out to be one of the most interesting systems problems in the entire project.
Building a Repeatable Evaluation Framework
Before evaluating different approaches, I needed a consistent way to measure accuracy. I developed a test suite of 90 sample inputs that represented the natural language I expected users to enter:
- "Dinner at Mario's €45 split 3 ways"
- "Flight tmr 9am"
- "Hotel checkout Sunday, Alice paid $200"
- "Museum tickets 15 each for 4 people"
These covered the typical use cases: expenses, itinerary items, split logic, dates, and participant tracking. I intentionally included variations in:
- Formality: "tomorrow" vs "tmr" vs "next Thursday"
- Currency formats: "€60" vs "60 euros" vs "60EUR"
- Split expressions: "split 4 ways" vs "15 each" vs "Bob owes 40%"
- Date references: Absolute dates, relative dates, and implicit timing
To evaluate each parser, I defined an error taxonomy:
- Amount errors
- Currency errors
- Date/time errors
- Participant/split errors
- Structural interpretation errors
Every parser was run against identical inputs, and accuracy was measured using this taxonomy. This made the trade-offs much clearer than a simple pass/fail system.
In the future, I plan to expand this with real user inputs to ensure broader coverage of input types (formal, casual, regional variations, etc.). But for the MVP, this test suite gave me a reliable benchmark to compare different parsing approaches.
Architecture Decisions
When evaluating parsing solutions, I optimized for several constraints:
Technical Complexity: Keep it simple.
Cost: Minimize ongoing expenses, especially during development and early user testing.
Latency: Users expect their inputs to be processed instantly without breaking the conversational flow.
Development Speed: I needed to move fast and validate the concept before over-investing in infrastructure.
Input Data Constraints: With limited real-world user data, I couldn't train custom models effectively. This pushed me toward off-the-shelf solutions.
Privacy – Especially important since users share trip information.
These constraints shaped my evaluation criteria.
Version 1: Regex Parsing
Fast, simple… and not sufficient for natural language.
Regex was the obvious starting point: fast, deterministic, and easy to run on-device. Perfect for the MVP mindset.
In theory, patterns like /(\\d+\\.?\\d*)\\s*(€|\\$|EUR|USD)/ should catch currency amounts. But real users don't write textbook sentences.
What Broke
- Typos: "60 euro" vs "60 euros" vs "60€"
- Order variations: "Split €60 four ways" vs "€60 split 4"
- Context-dependent phrases: "Dinner with Alice yesterday"
- Regional formats: "1.234,56 EUR" vs "$1,234.56"
I could patch individual cases, but the combinatorial explosion was endless.
Accuracy: 42/90 (~46%)
Great for textbook cases. Terrible for real-world use.
Verdict: Not good enough to be the flagship feature.
Version 2: Deterministic NLP Parser
A more sophisticated rules-based system with reinforcement learning.
I leveled up to a proper parser using:
- Tokenization and custom heuristics
chrono-nodefor date extraction- Currency normalization rules
- Split-type detection logic
- Reinforcement learning mechanism
This felt like real engineering. I built 100+ passing unit tests. The parser was fully offline, deterministic, and blazing fast (<10ms).
Reinforcement Learning Layer
I incorporated a reinforcement learning mechanism where users could provide feedback when the parser got it wrong. The workflow:
- User enters natural language input
- Parser generates a result
- User confirms if correct, or corrects any errors
- Corrections are scored and used to rank different parsing rules
- Next time a similar phrase appears, the highest-ranked rule is applied
What Worked
- Fully offline
- Extremely fast (<10ms)
- Predictable and debuggable
The idea was to catch more edge cases over time without manually coding every variation. However, this grew complex quickly:
- Insufficient data: Without enough user corrections, the scoring wasn't meaningful
- Rule explosion: The number of competing rules grew faster than the learning could optimize
- Debugging difficulty: It became hard to understand why certain rules won over others
While theoretically promising, the reinforcement learning approach needed significantly more input data to become useful.
What Still Broke
Real-world travel messages are just too varied:
- "Taxi 45 with John owes me later"
- "Marriott 15–20 Dec €200"
- "Museum tmr afternoon"
- "Brunch yesterday 30 each"
Even with reinforcement learning, complexity grew without improving overall reliability. Edge cases multiplied faster than I could address them.
Accuracy: 55/90 (~61%)
Better than regex — but still not good enough to be a flagship feature.
Verdict: Rule-based systems don't scale to real-world language. The long tail of expressions is endless, and reinforcement learning requires more data than I had available.
Version 3: On-Device LLMs
Promising accuracy, unusably slow without hardware acceleration.
To improve accuracy without sending data to external services, I tried running small LLMs locally:
- Phi-3-mini
- Mistral 7B
- Llama 3.2
These ran on a MacBook Air (CPU-only) using Ollama
What Worked
- Better flexibility than deterministic parsing
- Solid privacy guarantees
- No server dependency
- Handled ambiguity gracefully
What Didn't
Latency: Over 30 seconds per request
For interactive UI, this was a deal-breaker. Users expect instant feedback, especially when typing conversationally. Waiting 30 seconds for a preview completely destroyed the product experience.
Accuracy: ~60–70/90
Verdict: On-device LLMs aren't suitable for my use case since without hardware acceleration or quantization, latency is unacceptable for real-time experiences.
Version 4: Hosted LLM (GPT-4o-mini)
The first approach that actually felt "right."
I integrated GPT-4o-mini through a server-side API route with structured JSON output.
This version delivered:
- High accuracy across diverse input styles
- Robust parsing of dates, currencies, amounts, and participants
- Handling of typo-ridden or ambiguous input
- Ability to parse "dual" items (e.g., hotel = expense + stay)
- Significantly reduced maintenance burden
The key architectural decision was using a preview → confirm workflow:
User Input
↓
AI Parser (GPT-4o-mini)
↓
Structured JSON
↓
UI Preview (user can edit)
↓
User Confirms
↓
Database Save
This architecture naturally absorbs the ~1 second latency.
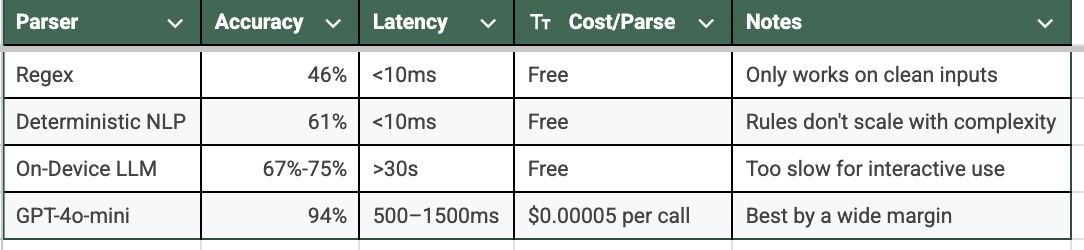
Latency: 500–1500ms
Acceptable for a preview flow.
Accuracy: 85/90 (~94%)
A dramatic improvement over all other approaches. The parser now handled:
- Typos and colloquialisms
- Relative dates ("tomorrow", "next Thursday")
- Multi-currency expressions
- Complex split logic
- Ambiguous phrasing
Cost & Privacy Tradeoffs
Cost:
- ~$0.00005 per parse
- ~10,000 parses/month → ~$0.50
- ~100,000 parses/month → ~$5.00
For the UX benefits and accuracy gains, this was an easy decision. Even at scale, the cost remains negligible compared to the value delivered.
Privacy Considerations:
Moving to a hosted LLM meant sending user input to OpenAI's servers. To address privacy concerns:
- Data Sanitization: User input is sanitized before sending to the API — removing any PII (personally identifiable information) when possible
- Structured Output: The API returns only classification data and intent mapping as JSON, not conversational responses
- No Training: Data sent to OpenAI's API is not used to train their models (per their API terms)
- Preview Flow: Users see and approve the parsed result before it's saved to the database
- Reduced data transfer: Only the minimum required text is sent to the model
While not as private as on-device processing, this approach balances privacy with usability. For a travel coordination app where users are already sharing information with their group, the tradeoff was acceptable.
Verdict: Accuracy was the defining feature. For Trip Threads, correctness is non-negotiable. A fast but wrong parser creates more frustration than value. The cost is negligible, and privacy concerns are mitigated through data handling practices.
The Comparison
What I Learned
Building this parser ended up being a full AI systems evaluation exercise — not just a feature implementation.
Key Lessons:
-
Accuracy beats speed when the feature is core to the product.
-
Rule-based systems don't scale to real-world language.
-
On-device LLMs are compelling, but require hardware-aware deployment.
-
A repeatable evaluation framework is essential for AI features.
-
Think like a systems PM.
-
Architectural context matters as much as model choice.
This project reinforced that AI features must be treated as systems with measurable KPIs and evolving constraints and not just as one-off model integrations.
What's Next
I'm exploring a hybrid inference strategy that balances accuracy, latency, cost, and privacy:
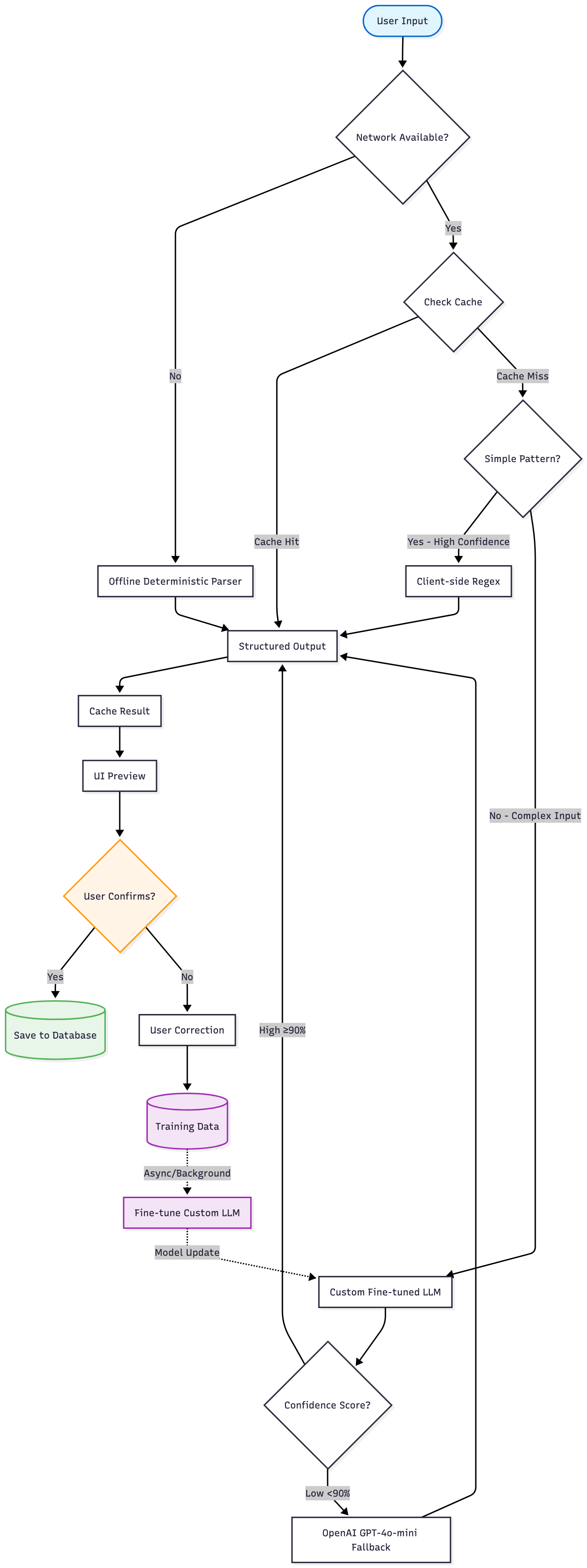
Future Architecture Goals:
- Custom fine-tuned LLM trained on user corrections and Trip Threads-specific patterns
- OpenAI fallback for edge cases where custom model has low confidence
- Client-side deterministic parsing for simple, high-confidence patterns (e.g., "€50")
- Result caching to improve speed and reduce cost
- Offline fallback using deterministic parsing when network unavailable
- Continuous learning from user corrections to improve the custom model
Over time, as we collect sufficient user inputs and corrections, we can train a custom model specifically for travel planning language. This would reduce dependency on external APIs, lower costs, and improve privacy — while maintaining the accuracy benefits of LLM-based parsing.
Closing Thoughts
Trip Threads started as a way to scratch my own itch around group travel planning. But the NLP parser became the most interesting part of the journey.
It forced me to think deeply about product trade-offs: accuracy vs. speed, privacy vs. capability, simplicity vs. robustness.
And it reminded me that the best solution isn't always the most technically elegant one — it's the one that delivers the best user experience within real-world constraints.
If you want to go deeper into the implementation, test suite, or architecture, feel free to reach out.
This post is part of my ongoing work on Trip Threads — a conversational travel planner built to make group coordination feel more human.